
If you build with large language models, your bill is not really priced in dollars. It is priced in tokens, and the relationship between the text you send and the tokens you pay for is rarely one-to-one. This guide explains exactly what a token is, how GPT, Claude and Gemini count them differently, what each model costs in June 2026, and how to use a free AI Token Calculator to estimate any API call in seconds.
What are AI tokens?
A token is the smallest chunk of text an LLM actually sees. Tokenizers split your input into sub-word units using an algorithm called Byte Pair Encoding (BPE), which learns the most common character sequences in a training corpus and assigns each a single integer ID. The model never sees letters or words - only those IDs.
A useful rule of thumb for English prose is roughly 4 characters or 0.75 words per token. So 1,000 tokens lands at about 750 English words.
The rule breaks the moment you leave plain prose:
- Code and JSON tokenize heavier because punctuation and indentation each get their own tokens.
- Non-Latin scripts (Chinese, Arabic, Hindi) can use 2-3x more tokens per character because the base BPE merges were trained mostly on English text.
- Emojis can take 3-6 tokens for a single visible character.
- Long URLs and base64 blobs are also expensive - they rarely match any common merges.
If you want to skip the math, paste any text into the AI Token Calculator to see the count for GPT-5, Claude 4.7, and Gemini 3.1 side-by-side.
How OpenAI, Claude & Gemini count tokens
Each vendor ships its own tokenizer, and only one of them is fully open.
OpenAI - tiktoken (open and exact)
OpenAI publishes its tokenizer as the open-source tiktoken library. GPT-4o and GPT-5 family models use the o200k_base encoding; GPT-4 and 3.5-era models use cl100k_base. Because the algorithm is public, any third-party counter that uses tiktoken returns the exact same token count OpenAI bills you for.
Anthropic - client.messages.countTokens()
Anthropic's tokenizer is not open-sourced. The only authoritative way to count Claude tokens is the count_tokens endpoint on the Messages API:
client.messages.count_tokens(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Hello, world"}],
)Anthropic has also flagged that Opus 4.7 uses a new tokenizer that can produce up to 35% more tokens for the same input text compared to earlier Claude models. That is a real cost surprise - switching from Sonnet 4.6 to Opus 4.7 is not just a price-per-token jump, it is also a token-count jump.
Google - countTokens endpoint
Gemini exposes a countTokens method on the generative model object. Like Anthropic, the underlying tokenizer is not open, so third-party estimators run at roughly ±5-10% accuracy for Claude and Gemini.
Why token count impacts API cost
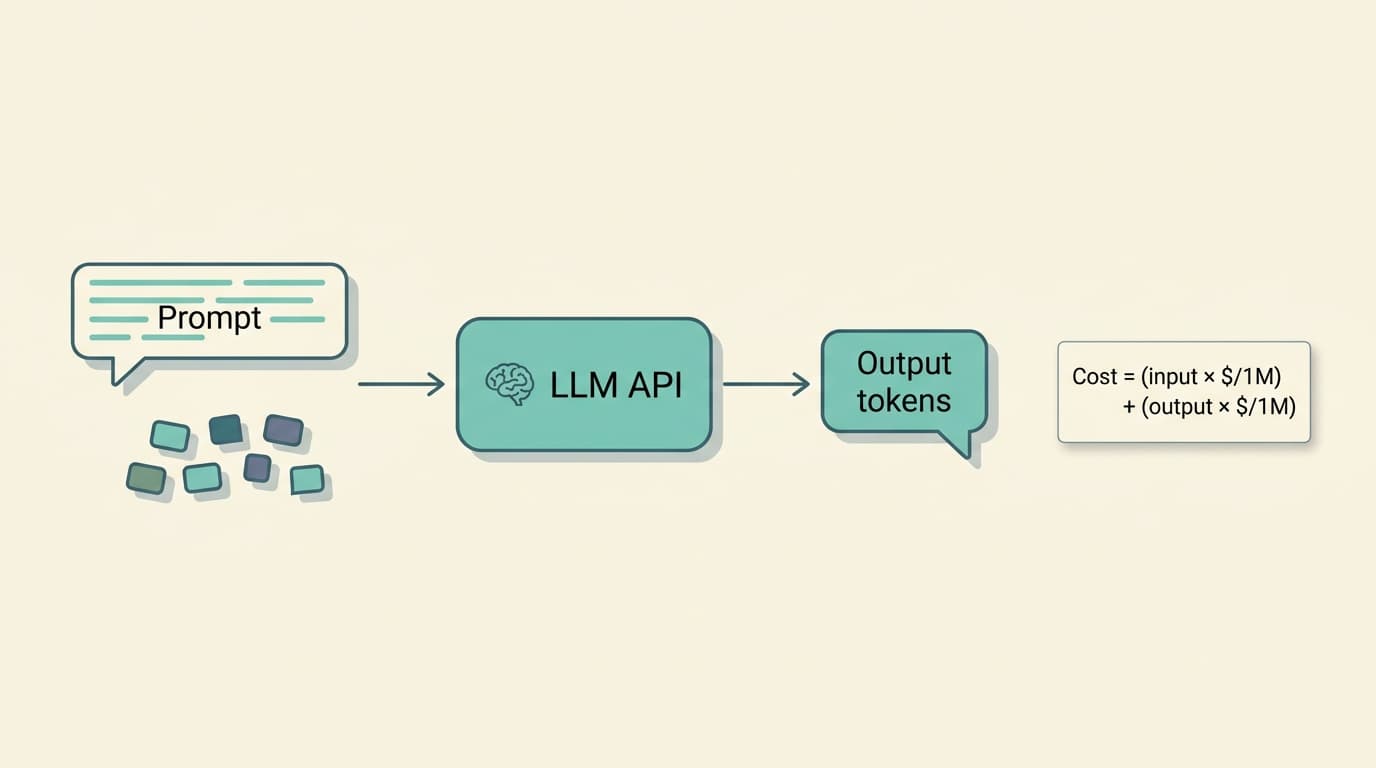
Every modern LLM API bills on a simple formula:
cost = (input_tokens / 1,000,000) × input_price
+ (output_tokens / 1,000,000) × output_priceWorked example. You send GPT-5 a 1,500-token prompt and it returns a 500-token answer:
- Input: 1,500 / 1,000,000 × $1.25 = $0.001875
- Output: 500 / 1,000,000 × $10.00 = $0.005000
- Total: $0.006875 per call
Multiply by 50,000 calls a month and that single endpoint is $343.75/month before any caching.
Input vs output tokens explained
Across every flagship model in 2026, output tokens cost 4-8x more than input tokens. GPT-5 is $1.25 in vs $10 out (8x). Claude Opus 4.7 is $5 in vs $25 out (5x). Gemini 2.5 Pro is $1.25 in vs $10 out (8x).
That asymmetry has a few practical consequences:
- System prompts, RAG context, tool/function schemas, and chat history all count as input. A 4 KB system prompt sent to 10,000 requests a day is 10,000 × ~1,000 input tokens, every day.
- Output is what kills budgets. Long-form generations, JSON dumps, and reasoning traces inflate the expensive side of the equation.
max_tokensis a budget cap, not just a length limit. Setting a sensible cap prevents runaway completions.
How to estimate AI API pricing
You have three realistic options.
1. Rule of thumb
Multiply English word count by 1.33 to get a token estimate. Good enough for ballpark planning, useless for budgets.
2. Official tokenizer libraries
- OpenAI:
tiktoken.encoding_for_model("gpt-5") - Anthropic:
client.messages.count_tokens(...) - Google:
model.count_tokens(prompt)
Use these inside CI or in production code where billing accuracy matters.
3. Paste-and-go calculator
For estimating during prompt design, model comparison, or capacity planning, a hosted calculator is the fastest path. Paste a prompt, pick the models, and see input/output cost across every relevant provider at once.
Skip the math
AI Token Calculator
Compare cost across 40+ OpenAI, Claude, and Gemini models in one click - input, output, and total side-by-side.
Live 2026 pricing table
All prices are USD per 1M tokens. Last verified 2026-05-23 against vendor pricing pages (OpenAI, Anthropic, Google).
OpenAI
| Model | Input $/1M | Output $/1M |
|---|---|---|
| GPT-5 | 1.25 | 10.00 |
| GPT-5 Mini | 0.25 | 2.00 |
| GPT-5 Nano | 0.05 | 0.40 |
| GPT-5 Pro | 15.00 | 120.00 |
| GPT-5.4 | 2.50 | 15.00 |
| GPT-5.4 Mini | 0.75 | 4.50 |
| GPT-5.4 Nano | 0.20 | 1.25 |
| GPT-4.1 | 2.00 | 8.00 |
| GPT-4.1 Mini | 0.40 | 1.60 |
| GPT-4.1 Nano | 0.10 | 0.40 |
| GPT-4o | 2.50 | 10.00 |
| GPT-4o Mini | 0.15 | 0.60 |
| o3 | 2.00 | 8.00 |
| o4 Mini | 1.10 | 4.40 |
Anthropic (Claude)
| Model | Input $/1M | Output $/1M |
|---|---|---|
| Claude Opus 4.7 | 5.00 | 25.00 |
| Claude Opus 4.6 | 5.00 | 25.00 |
| Claude Opus 4.5 | 5.00 | 25.00 |
| Claude Opus 4.1 | 15.00 | 75.00 |
| Claude Sonnet 4.6 | 3.00 | 15.00 |
| Claude Sonnet 4.5 | 3.00 | 15.00 |
| Claude Haiku 4.5 | 1.00 | 5.00 |
| Claude Haiku 3.5 | 0.80 | 4.00 |
Google (Gemini)
| Model | Input $/1M | Output $/1M |
|---|---|---|
| Gemini 3.1 Pro Preview (≤200k) | 2.00 | 12.00 |
| Gemini 3.1 Pro Preview (>200k) | 4.00 | 18.00 |
| Gemini 3 Flash | 1.50 | 9.00 |
| Gemini 2.5 Pro (≤200k) | 1.25 | 10.00 |
| Gemini 2.5 Pro (>200k) | 2.50 | 15.00 |
| Gemini 2.5 Flash | 0.30 | 2.50 |
| Gemini 2.5 Flash-Lite | 0.10 | 0.40 |
For a live, interactive version of this table, see the AI Token Calculator.
Prompt examples with token counts
Three real-world prompts, with rough token counts and per-model cost. Output is assumed at 250 tokens unless noted.
1. Short chat turn (~25 input tokens)
What's the difference between SSE and WebSockets in one paragraph?| Model | Input cost | Output (250) | Total |
|---|---|---|---|
| GPT-5 Nano | $0.0000013 | $0.0001 | ~$0.0001 |
| GPT-5 | $0.000031 | $0.0025 | ~$0.0025 |
| Claude Sonnet 4.6 | $0.000075 | $0.00375 | ~$0.0038 |
2. RAG-style call with 5 KB context (~1,400 input tokens)
A system prompt plus three retrieved passages totaling ~5 KB of text.
| Model | Input cost | Output (500) | Total |
|---|---|---|---|
| GPT-5 Mini | $0.00035 | $0.001 | ~$0.0014 |
| Claude Haiku 4.5 | $0.0014 | $0.0025 | ~$0.0039 |
| Gemini 2.5 Flash | $0.00042 | $0.00125 | ~$0.0017 |
3. Code generation (~600 input, 1,200 output)
A function spec plus existing code context, with a longer generated answer.
| Model | Input cost | Output cost | Total |
|---|---|---|---|
| GPT-5 | $0.00075 | $0.012 | ~$0.0128 |
| Claude Sonnet 4.6 | $0.0018 | $0.018 | ~$0.0198 |
| Gemini 3 Flash | $0.0009 | $0.0108 | ~$0.0117 |
The output column dominates - exactly as the input-vs-output ratio predicts.
How to reduce LLM costs
1. Right-size the model
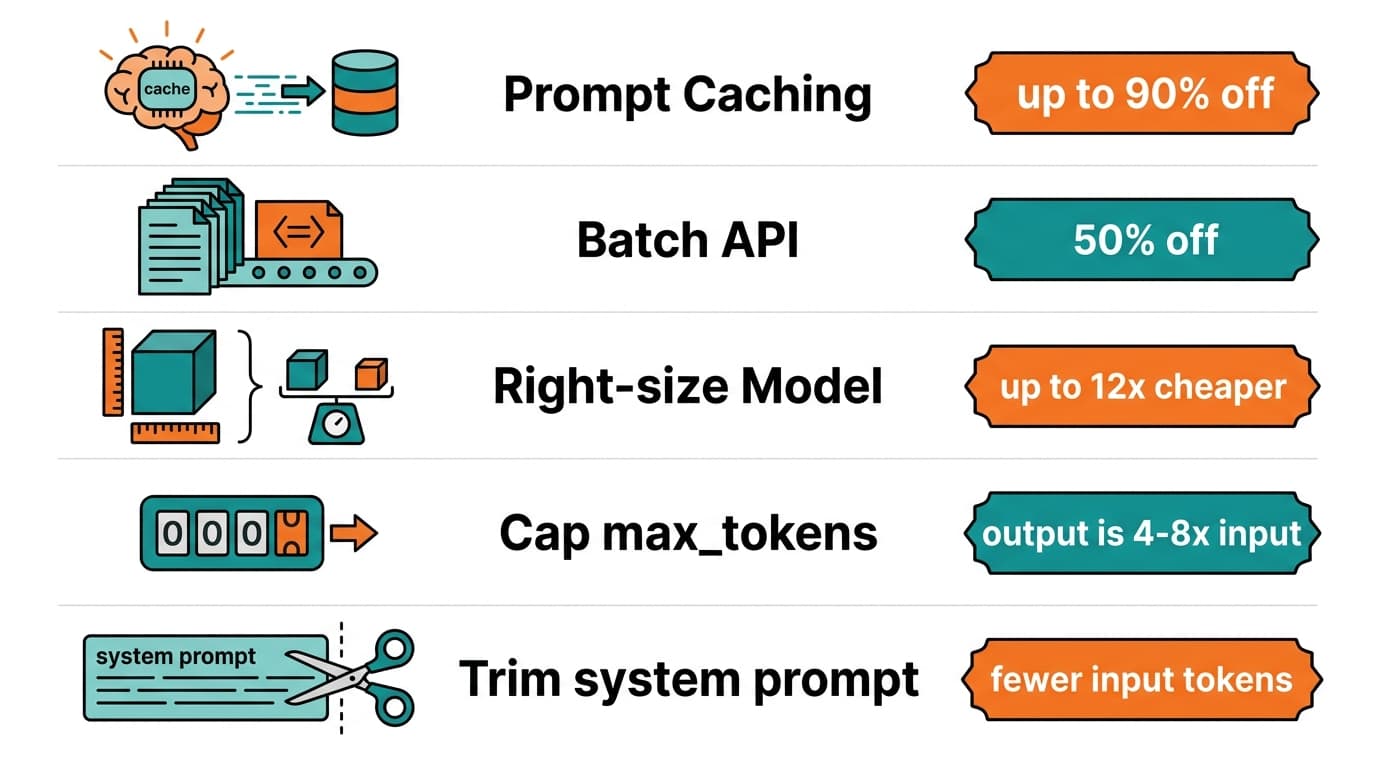
A surprising amount of production traffic is classification, extraction, summarization, or short chat - none of which needs a frontier model. Move that traffic to GPT-5 Nano, GPT-4.1 Nano, Claude Haiku 4.5, or Gemini 2.5 Flash-Lite and you typically cut cost 10-25× with negligible quality loss.
2. Prompt caching
- Anthropic prompt cache hits cost 10% of standard input - a 90% discount on the cached portion. Cache writes are 1.25× input for a 5-minute TTL and 2× input for a 1-hour TTL.
- OpenAI cached input is roughly 10% of standard input. For GPT-5 that means cached input lands around $1/M vs $1.25/M standard.
If you have a long system prompt or stable RAG context that repeats across calls, caching pays for itself quickly.
3. Batch API
Anthropic's Batch API is 50% off both input and output across current Claude 4.x models. OpenAI offers a similar 50% Batch discount with a 24-hour SLA. Anything non-interactive - evals, bulk extraction, overnight summarization - belongs on Batch.
4. Cap max_tokens
Because output is 4-8× more expensive than input, an unbounded max_tokens is the single most common budget leak. Set it to the shortest value your task actually needs.
5. Trim the system prompt
Every token in your system prompt is sent on every request. Audit it quarterly; you will usually find 30-50% of it is no longer needed.
6. Semantic caching at the gateway
Tools like a small embedding-based cache in front of your LLM endpoint can short-circuit repeat questions entirely. For FAQ-style traffic this is often the highest-leverage optimization.
7. Use structured outputs
JSON mode and tool calling reduce the retry rate from malformed responses, and retries are 100% pure waste.
Best AI models for cheap inference
| Tier | Model | Input $/1M | Output $/1M | Sweet spot |
|---|---|---|---|---|
| Ultra-budget | GPT-5 Nano | 0.05 | 0.40 | Classification, routing, short replies |
| Ultra-budget | Gemini 2.5 Flash-Lite | 0.10 | 0.40 | High-volume extraction |
| Balanced | Claude Haiku 4.5 | 1.00 | 5.00 | Customer support, summarization |
| Balanced | Gemini 2.5 Flash | 0.30 | 2.50 | Mid-tier chat, RAG |
| Premium | GPT-5 | 1.25 | 10.00 | General-purpose agent core |
| Premium | Claude Sonnet 4.6 | 3.00 | 15.00 | Coding, structured reasoning |
A common production pattern is to route 80% of traffic to a Nano/Flash-Lite tier, escalate 15% to a balanced tier, and reserve a frontier model for the last 5% that genuinely need it.
Free AI Token Calculator
iToolVerse's AI Token Calculator covers every model in the tables above. Paste a prompt, choose any combination of OpenAI, Claude, and Gemini models, and see input cost, output cost, and total side-by-side. It is free, runs entirely in your browser, and the pricing table is refreshed against vendor pages monthly. The tool is one of 46+ free utilities on iToolVerse, and the underlying pricing data lives in the public repo for full transparency.
Compare every model at once
AI Token Calculator
Paste a prompt, pick GPT-5, Claude 4.7, Gemini 3.1 (or any of 40+ others), see total cost side-by-side.
